3. 태양광 발전소의 일사량과 출력 예측
본 논문에서는 전라남도에 위치한 태양광 발전소의 일사량과 태양광 출력 예측을 위해 태양광 발전소 주변의 온도, 습도, 일사량 관측이 가능한 기상관측소들을 파악하고 이에 대해 상관관계 감쇠 거리를 계산했다. 온도, 습도, 일사량 데이터를 가지고 있는 전라남도, 전라북도, 경상남도 지역에서 16개의 기상 관측소를 선정하였고, 모두 CDD 범위 내에 들어가는 것을 확인하였다. 더 정확한 예측 결과를 만들어 내기 위해 상위 50%의 상관관계를 갖는 거리 내에 있는 관측소를 선정하였고 총 8곳이 선정되었다.
미래의 태양광 발전 출력 예측을 하기 위해서는 예측이 진행되는 시점의 데이터가 준비되어있어야 한다. 현재 기상청에서는 온도, 습도 정도의 정보만 주간 단위로 제공을 해주고 있으므로 일사량 데이터에 대한 예측이 필요하다. 일사량 예측을 위해 각 기상 관측소의 온도, 습도, 과거 2일의 일사량 데이터를 사용했으며, 앙상블 모델을 기본으로 사용한 배깅 모 델을 통해 각 지점의 일사량 예측하고 예측한 각 지점의 일사량을 통해 목표 지점의 일사량을 추정했다.
3-1. 일사량 예측 데이터 전처리
일사량 예측은 태양광 발전소 주변 지역인 전라남도, 전라북도, 경상남도에 위치한 기상관측소 중 상관관계 감쇠 거리 계산을 통해 선정된 8개의 기상관측소의 데이터를 사용하였다. 온도, 습도, 일사량을 1시간 단위로 정리하였으며, 학습 데이터(training data)와 평가 데이터(test data)의 비율은 약 85:15, 평가 데이터는 월별, 계절별 특성을 고려하여 임의 추출이 아닌 매월 마지막 5-6일로 지정하였다.
3.2 일사량 예측 피처 엔지니어링
각 기상 관측소의 온도, 습도, 일사량 상관관계를 분석해보니 온도, 습도와 일사량에 대한 상관관계 계수가 높지 않았다. 이에 과거 이틀 치 일사량 데이터를 함께 분석했으며, 모두 온도, 습도보다 높은 상관관계를 보였다. 예측에서 입력변수인 피처(Feature)는 온도, 습도, D-2 일사량, D-1 일사량이며 예측의 대상인 일사량은 레이블(Label)로 지정하였다. 전체 변수의 상관관계는 피어슨 상관계수(Pearson’s correlation coefficient)를 통해 계산하였다.
3.3 일사량 예측 모델링과 성능평가
일사량 예측을 위해 머신러닝의 앙상블 모델 중 하나인 배깅 모델을 사용하였으며, 기존의 배깅 모델과는 다르게 기본을 의사결정나무가 아닌 랜덤 포레스트와 라이트 그라디언트 부스팅 머신을 사용하였다. 결과값 선정은 두 가지 기본 모델 중 더 낮은 오차를 가지고 있는 모델을 선정했고, 예측한 값을 통하여 그 기간의 태양광 발전소의 일사량을 ADW 보간법을 통하여 추정하였다. 예측 모델의 효과를 검증하고 성능을 평가하기 위해 평균 절대 오차 (Mean Absolute Error)와 평균 제곱 오차(Mean Square Error)를 사용하였다.
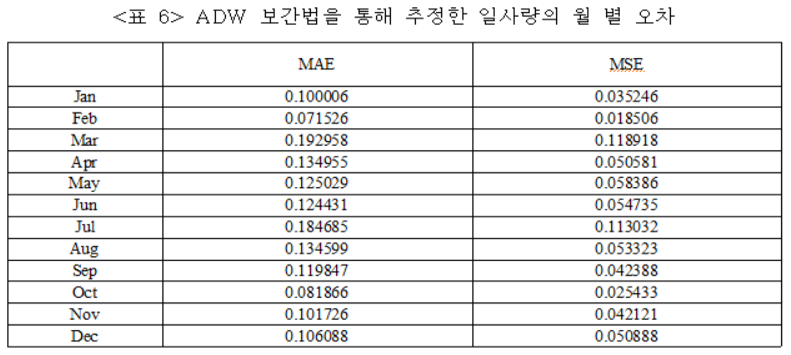
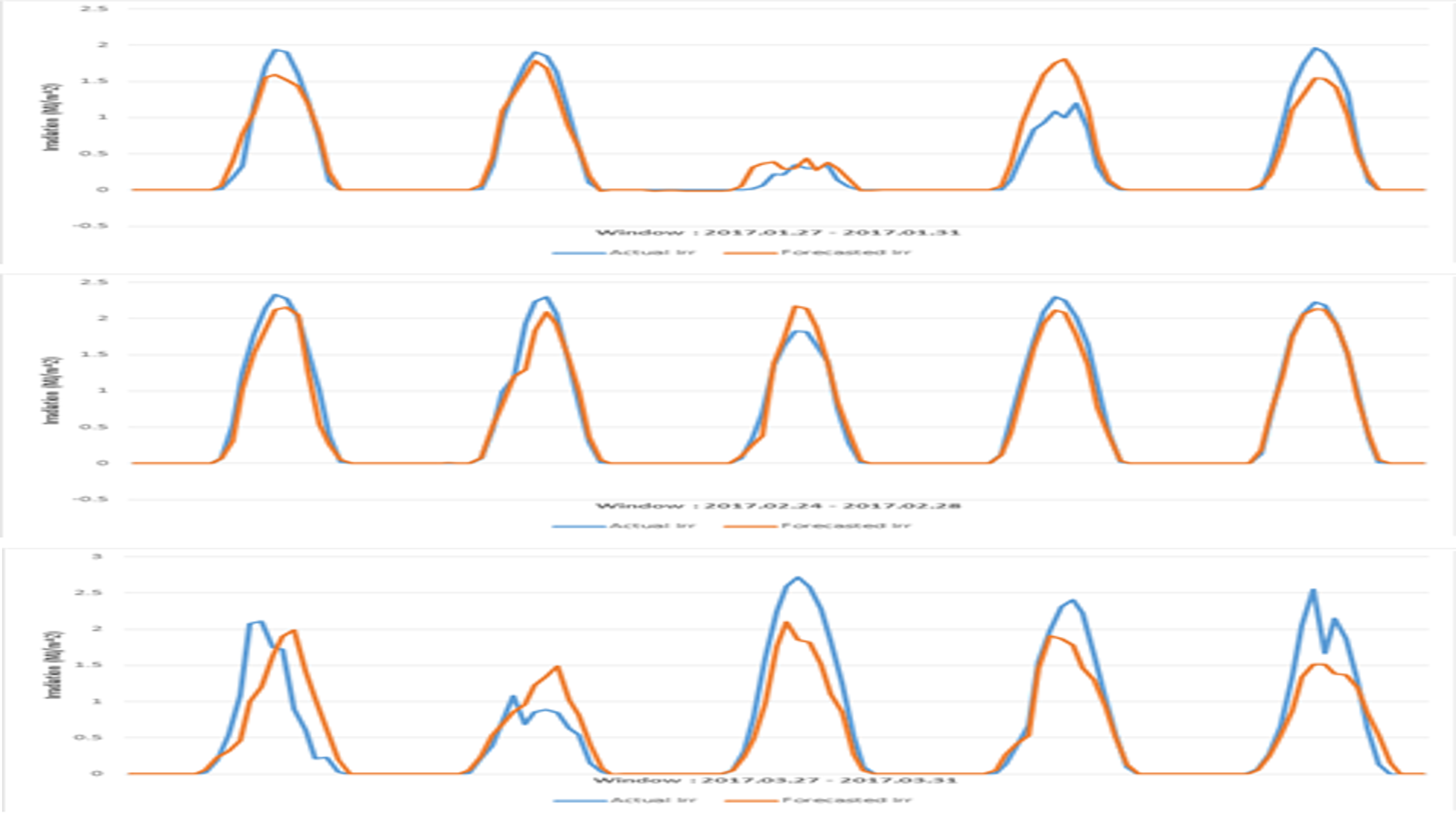
3.4 태양광 출력 예측 데이터 전처리
태양광 출력 예측에서 사용하는 데이터는 온도, 습도, 일사량이다. 온도와 습도는 예보되는 데이터로 얻을 수 있기 때문에 예측 시점에서 얻을 수 없는 값인 일사량을 머신러닝 기법과 ADW 보간법을 통해 추정하였다. 정리해보면 온도, 습도, 일사량 모두 CDD 범위 내에서 선정된 기상 관측소의 데이터를 추정하여 얻지만, 온도와 습도는 미래의 값이 제공되므로 제공되는 값을 사용하여 추정하였고, 일사량은 제공되지 않아 자체적으로 예측하고 예측값을 통해 목표 지점의 일사량을 추정하였다. 예측을 진행하고자 하는 태양광 발전소는 전라남도 영암에 위치한 곳이며 2017년 1년 치 데이터를 이용하여 예측 모델을 훈련시켰고, 앞서 선정된 기상 관측소를 통해 추정한 기상 데이터를 입력하여 예측을 진행했다. 출력량 예측은 2017년 1년 치 데이터를 사용하였다. 온도, 습도, 일사량, 출력량을 1시간 단위로 정리하였으며, 일사량 예측과 마찬가지로 학 습 데이터와 평가 데이터의 비율은 약 85:15이며 평가 데이터는 월별, 계절별 특성을 고려하여 임의 추출이 아닌 매월 마지막 4~5일로 지정하였다.
3.5 태양광 출력 예측 피처 엔지니어링
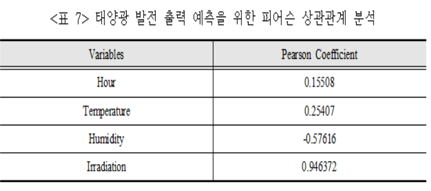
온도, 습도, 일사량을 피처로 지정하고 출력을 예측하는 항목인 레이블로 지정하였으며, 피어슨 상관계수를 계산하였다. 일사량, 습도, 온도, 시간 순으로 출력에 영향을 미치는 것을 확인할 수 있다.
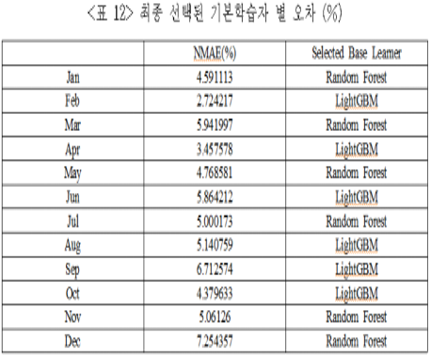
3.6 태양광 발전 출력 예측 하이퍼 파라미터 최적화
모델이 데이터를 통해 학습하면서 성능을 높이기 위해 모델 내부에서 자체적으로 결정되는 매개변수인 파라미터와 달리, 하이퍼 파라미터는 초매개변수로써, 모델을 만들 때 사용자가 직접 설정하는 값이다. 하이퍼 파라미터는 모델의 성능에 큰 영향을 주지만, 학습을 하면서 스스로 찾는 값은 아니기 때문에 사용자가 여러 값들을 직접 수정해가면서 최적의 값을 찾아가야 한다. 최적의 하이퍼 파라미터를 찾는 방법에는 여러 가지가 있으며, 본 논문의 예측에서는 모델의 기본학습자인 라이트 그라디언트 부스팅 머신과 랜덤 포레스트의 하이퍼 파라미터 최적화를 위해 GridsearchCV를 사용했다.

3.7 태양광 발전 출력 예측 모델링과 성능평가
태양광 발전 출력 예측 모델의 효과를 검증하고 성능을 평가하기 위해 NMAE(%)를 사용했다. NMAE는 예측 및 추세 추정의 정확성을 평가하는 데 주로 사용한다.
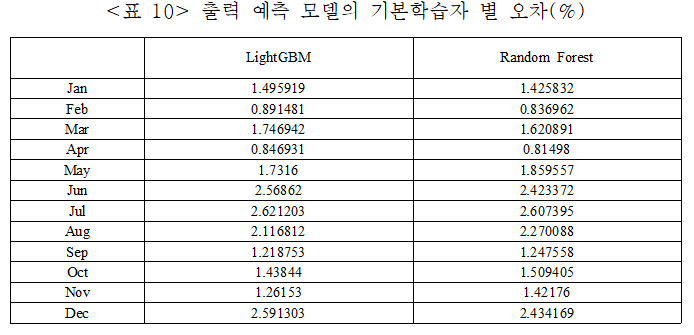
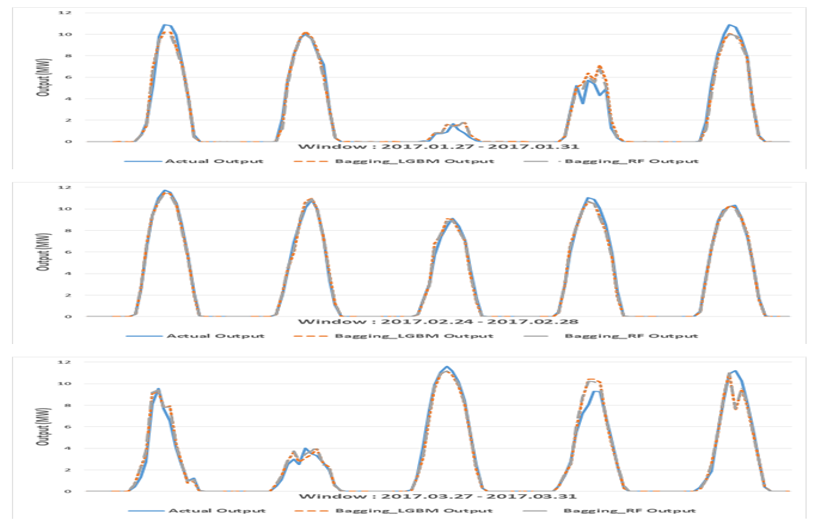
3.8 예측 일사량을 이용한 태양광 발전 출력 예측
최종적으로 만들어진 예측 모형에 보간법으로 추정한 온도, 습도, 예측한 일사량을 입력하여 태양광 발전소의 출력 값을 예측한다. 예측한 결과를 실제 출력 값과 비교해야 하므로 평가 기간은 위와 마찬가지로 2017년 매월 마지막 4-5일로 정했으며, 알고 있는 온도, 습도 데이터 그리고 예측한 일사량을 사용하는 것이므로 실제 미래의 출력 값을 예측하는 조건과 동일하다.