1. 개요
- 파리협정은 재생에너지원을 통한 에너지 발전의 필요성을 강조하고 변동성을 가지고 있는 발전 시스템을 어떻게 관리하고 통합할 것인지에 대한 연구를 동기 부여하는 계기가 됨
- 미래의 세계 에너지 공급에 있어 가장 중요한 도전 과제 중 하나는 재생에너지원을 기존 또는 미래의 에너지 공급 구조에 대규모로 통합하는 것
- 재생에너지원의 변동성과 불확실성은 전력 계통의 안정성에 영향을 줄 수 있는 요소로 반드시 다루어지고 해결되어야 하는 문제점으로 부상함
2. 문제점
- 재생에너지의 근본적인 문제점은 간헐성, 변동성 그리고 이로 인한 계통연계의 불안정성
- 재생에너지의 보급이 확대되어 재생에너지원의 계통으로의 침투가 증가할 때 curtailment 문제
- 전력 계통으로의 재생에너지의 통합은 예측이 어렵고 간헐적인 특성으로 인해 계통 관리 및 공급과 수요의 균형 지속성의 복잡성 강화
- 특히 태양광과 풍력 같은 에너지원은 출력이 안정적이지 않기 때문에 큰 문제를 야기할 수 있음
전력계통 운영자는 언제라도 전기 생산과 소비 사이의 정확한 균형을 보장해야 하기 때문에 대용량의 재생에너지원의 계통 연계에 대비하여 효과적인 예측 기법이 중요해졌다.
3. 해결방안
3-1. 출력 예측
재생에너지원의 계통 연계 문제점을 해결하기 위한 재생 에너지원 출력 예측의 효과는 아래와 같다.
- 전력계통의 효과적인 운영
- 재생에너지원에서 발생하는 에너지 변동성에 대한 최적의 관리
- 예비력 산정
- 전력 계통의 스케쥴링
- 혼잡 관리
- Stochastic production을 통한 최적의 저장장치 관리
- 전력 시장에서의 생산된 전력 트레이드
- 전력 생산 비용의 감소
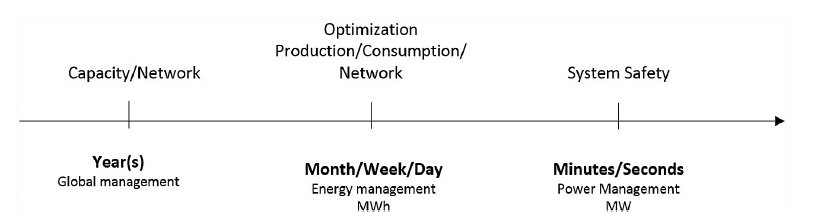
3-1-1. 예측 기법
변동성 전원의 발전 예측에는 크게 두 가지 접근 방법이 있다. 첫 번째 방법은 분석 방정식을 사용하여 시스템을 모델링하는 것이며, “white box"로 명시한다. 두 번째 방법은 통계 및 machine learning을 사용하여 출력을 직접 예측하는 것이다. 또한 두 가지 방법을 혼합하여 사용되기도 하며, 하이브리드 모델 또는 “grey box"로 명시한다.
White box models
White box meodel은 과거 데이터가 필요하지 않으며, 발전소 건설 전에 발전소의 기술사양, NWP을 알고 있으면 전력 출력을 알 수 있다. 그러나 오차의 주된 원인인 NWP에 대한 의존성이 매우 높다.
Statistical models
Statistical models을 모델링하기 위한 시스템 내부 정보가 필요 없다. 이는 과거 데이터에 대한 관계를 추출하여 발전소의 미래를 예측할 수 있는 데이터 기반 접근방식이며, 정확한 예측을 위해서는 과거 데이터의 품질이 필수적이다. 입력의 측정과 관련된 systematic errors를 교정하는 능력이 이 방법의 이점이다.
Regressive methods
Regressive methods는 종속 변수(재생 에너지 출력)와 예측 변수라고 불리는 일부 독립 변수 사이의 관계를 추정한다. 시계열의 처리 방법에 따라 추가 분류가 나타난다.
Machine learning methods
기계 학습 모델은 표현이 불가능한 경우에도 입력과 출력 사이의 관계를 찾을 수 있다. 이 특성은 패턴 인식, 분류 문제, 스팸 필터링, 데이터 마이닝 및 예측 문제 등 많은 경우에 기계 학습 모델을 사용할 수 있도록 한다.
Artificial Intelligence (AI) techniques
Artificial Neural Networks (ANNs)
K-Nearest Neighbors (k-NN)
Support Vector Machines (SVM)
Random Forests (RF)
Hybrid models
단일 모델은 각 기법이 데이터를 변환하는 방식에 의해 일부 정보를 생략할 수 있다. 따라서, 정확도를 향상하기 위해 각각 기법의 장점을 뽑아내어 결합하는 것도 일반적이며, 이는 혼성, 혼합, 결합 또는 앙상블 모델로 표현된다.
예측에 사용된 기법 중에서 가장 일반적인 접근방식은 통계적 기법의 사용이며, 특히 ANN은 24%를 차지한다.
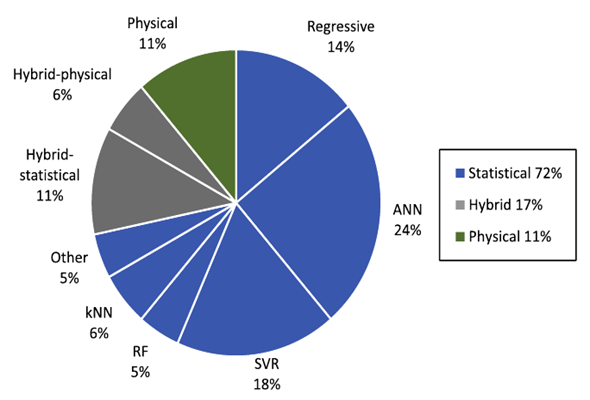
3-1-2. Machine learning methods
기계 학습은 컴퓨터 과학의 하위 분야로 인공지능 방식으로 분류된다. 기계 학습 모델은 표현이 불가능한 경우에도 입력과 출력 사이의 관계를 찾을 수 있으며 이 특성은 패턴 인식, 분류 문제, 스팸 필터링, 데이터 마이닝 및 예측 문제 등 많은 경우에 기계 학습 모델을 사용할 수 있도록 한다.
3-1-2-1. Classification and data preparation
Machine learning은 데이터를 통해 학습한다. 문제를 효과적으로 해결할 수 있도록 알맞은 데이터를 선택하고 적절하게 준비하는 것이 중요하다.
- Discriminant analysis and principal component analysis (PCA)
- PCA는 직교 변환(orthogonal transformation)을 사용하여 상관관계가 있을 수 있는 변수의 일련의 관측치를 성형적으로 상관관계가 없는 변수의 값으로 변환하는 통계적 기법
- Naive Bayes classification and Bayesian networks
- Naïve Bayes classification는 형상(features)들 사이에서 강한 독립성을 가진 Bayes 정리 적용하는 간단한 확률적인 classifier의 계열
- Bayesian network는 확률론적 그래픽 모델로서, 지시된 반복 그래프를 통해 일련의 무작위 변수와 조건부 의존성을 나타내는 통계 모델의 일종
- Data mining approach
- Data mining은 매우 큰 데이터 집합에서 가장 중요한 정보를 추출하는 방식
- Data mining에서 수집 도니 데이터는 예측 모델에서 사용하기 전에 주요 정보를 강조하기 위해 분석됨
3-1-2-2. Supervised learning
컴퓨터에게 입력과 원하는 출력이 주어지며, 이를 통해 출력에 입력을 mapping 하는 일반적은 규칙을 배우는 것이 목표이다. Training data를 분석하고 추론된 function을 생성하는 것이 supervised learning의 기능이다.
- Linear Regression
- Generalized Linear Models
- 통계에서의 GLM은 정규 분포 이외의 오류 분포 모형을 갖는 반응 변수를 허용하는 일반 선형 회귀의 유연한 일반화(flexible generalization)함
- GLM은 선형 모형을 링크 함수를 통해 반응 변수와 관련되도록 허용하고 각 측정의 분산 크기를 예측 값의 함수로 간주하여 선형 회귀 분석을 일반화함
- Nonlinear Regression
- Artifial Nerual Networks(ANN)은 데이터 분석 및 예측에서의 유용성 때문에 기상학에서 비선형 회귀 및 문제 분류에 많이 쓰이고 있음
- 비선형 방법으로 예측하는 시계열 영역에서 우세
- Support Vector Machines / Support Vector Regression
- Support Vector Machine은 분류 작업 및 회귀 문제에 사용되는 또 다른 kernel 기반의 기계 학습 기법
- Support vector regression은 support vector machines을 회귀 문제에 적용하는 데 기반
- 시계열 예측 작업에 성공적으로 적용됨
- Decision Tree Learning (Breiman bagging)
- 입력 X1,X2,….,Xp의 response 또는 class Y를 예측
- 각 항목을 키워감으로써 이루어짐
- Tree의 Node에서 입력 중 하나에 대한 테스트는 Xi가 적용되었다고 말하며, 시험 결과에 따라 나무의 왼쪽 또는 오른쪽 하위 나뭇가지가 선택되고 결국 나뭇잎 노드에 도달하면 예측이 이루어짐
- Nearest Neighbor
- Nearest neighbor neural network (k-NN)은 인스턴스 기반 학습의 일종으로, 함수는 국부적으로 근사되고 모든 계산은 분류가 될 때까지 딜레이 됨
- K-NN 알고리즘은 가장 간단한 머신 러닝 알고리즘 중 하나이며, regression과 classification 둘 다에서 가까운 정도에 대한 기여도에 가중치를 할당하는 데 유용함 (가장 가까운 것이 먼 것보다 평균에 더 많이 기여)
- Markov Chain
- Domain을 예측하는 데 사용됨
- 현재의 상태를 고려할 때, 미래 상태는 과거 상태와 독립적임을 의미하는 Stochastic 프로세스임
- 미래 상태는 결정론적 상태 대신 확률론적 프로세스를 통해 도달
3-1-2-3. Unsupervised learning
Unsupervised learning은 Supervised learning model과 달리 출력에 대한 지식 없이 이것의 입력에 숨겨진 구조를 찾을 수 있으며, 데이터를 사전 처리하는 데 사용되는 데이터 마이닝 방법을 기반으로 한다.
- K-means and k-methods Clustering
- 신호 처리에서 파생된 벡터 정량화 방법으로, 데이터 마이닝에서 많이 사용됨
- N개의 관측치를 각 관측치가 군집의 원형 역할을 하는 가장 가까운 평균을 가진 군집에 속하는 K개의 군집으로 분할하는 것을 목표로 함
- 시계열 동작을 모델링하고 데이터를 군집화하여 입력 공간의 패털을 찾을 목적으로 데이터에서 유용한 정보를 추출하는 데 초점을 맞춤
- Hierarchical Clustering
- 데이터 마이닝 및 통계에서, 계층적 군집화는 군집의 계층을 구척 하려는 군집 분석의 한 방법
- 계층적 군집화는 뿌리와 잎을 모두 포함하는 “Dendrogram”이라는 나무 구조에서 나타낼 수 있는 군집의 계층을 만듦
- 나무의 뿌리는 모든 관측치를 포함하는 단일 성단으로 구성되는 반면, 잎은 개별 관측치에 해당
- 알고리듬은 과정이 잎에서 시작하여 연속적으로 군집을 병합하는 직접성 또는 뿌리부터 시작하여 군집을 재귀적으로 분할하는 분열성 중 하나
- Gaussian Mixture Models
- 비선형 모델링에서는 비교적 최근에 개발된 것
- 무한히 많은 변수에 대한 다변량 가우스 분포를 일반화한 것
- Cluster Evaluation
- 군집화의 일반적인 목표 기능은 군집 내 높은 유사성과 낮은 유사성을 달성하는 목표를 공식화하는 것이며 이는 군집화의 품질에 대한 내부 기준
3-1-2-4. Ensemble learning
앙상블 학습의 기본 개념은 여러 기본 학습자를 ensemble members로서 훈련시키고, 이들의 예측들을 목표 데이터 세트에서 상관없는 오차를 가진 ensemble members보다 평균적으로 더 좋은 성능을 가져야 하는 하나의 결과로 합치는 것이다. 즉, 앙상블은 더 나은 가설을 만들기 위해 여러 가설을 결합하는 것이다.
- Boosting
- 강한 “committee”를 만들기 위해 많은 weak classifiers를 결합하는 방법으로 부상
- 좋지 않은 분류에 더 많은 중요성을 주는 반복적인 과정이며, 이 간단한 전략은 분류 성과를 획기적으로 향상시킴
- Bagging
- Bootstrap이라고 불리며, 통계 분류와 회귀 분석에서 사용됨
- 기계 학습 알고리즘의 안정성 및 정확도를 향상시키기 위해 설계된 ensemble meta-algorithm
- Random Subspace
- 제안된 방법론에 사용되는 기계 학습 도구는 Random Forests에 기초
- 이는 다수의 의사결정 트리의 집합 또는 합성으로 구성됨
- 각각은 훈련 세트에서 대체로 추출한 표본으로 만들어진 것이 출력 그룹
- Predictors Ensemble
- 앙상블 기반의 ANN 및 기타 기계 학습 기술은 글로벌 radiation modelling의 여러 연구에서 사용되었으며, 기존 회귀 모델에 비해 더 나은 성능과 일반화 기능을 제공
3-2. ESS(Energy Storage System)
3-2-1. 에너지 저장장치
- 에너지 저장장치는 과거 가격 예측으로 인해 경제적으로 비용 효율적인 다른 대안들과의 비교에서 배제되었음
- 그러나 최근 저장장치에 대한 가격 인하 및 앞으로도 가격이 떨어질 것이라는 예상으로 저장장치에 대한 검토가 늘어날 것으로 전망
- 에너지 저장장치의 가격 경쟁력과 신재생 에너지의 가치가 증가하면서 에너지 저장장치의 가치가 올라갈 것으로 전망
3-2-2. 에너지 저장장치의 용량
- 에너지 저장장치의 용량은 power capacity와 energy capacity에 의해 결정
- Power capacity (충, 방전 전력)
- 장치가 충전 또는 방전할 수 있는 전력
- 기존 발전 플랜트와 같이 kW 또는 MW의 단위로 측정
- Energy capacity (배터리 용량)
- 저장된 에너지의 양
- KWh 또는 MWh의 단위로 측정
3-2-3. 에너지 저장 솔루션
- 시스템 운영에 대한 완전한 예측을 포함시키는 것은 필수적
- 재생에너지의 큰 변동성을 방지
- 다양한 스토리지 시스템이 개발 중
- 변동성 전원이 생산하는 과잉 전력과 에너지를 흡수하여 피크 시간대에 방출
- 변동성을 낮추며 전력 품질의 안정성을 유지
3-2-4. 스토리지의 옵션에 따른 세 가지 범주
- Bulk energy storage or energy management : 생산과 소비의 타이밍을 분리
- Distributed generation or bridging power : Peak shaving (분~시간)
- Power quality storage with a time scale of about several seconds : 최종 사용 전력 품질의 연속성을 보장 (몇 초)
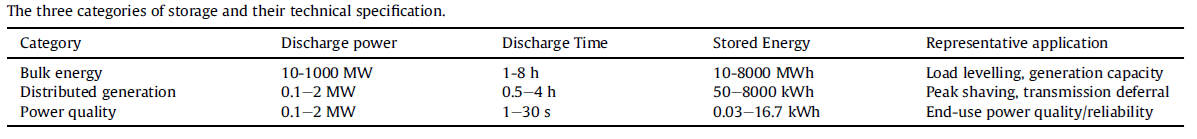
- At the shortest timescale (seconds to minutes)
- 운영 예비력 제공 (주파수 조정)
- 상대적으로 작은 시장의 규모와 수요반응자원, 재생에너지의 출력제한과 같은 다른 발전원들의 경쟁들로부터 제한됨
- At the longer timescales (up to several hours)
- 피크 출력 제공 (off-peak to peak), 피크출력 : 베이스 부하를 초과하는 피크 부하 부분을 공급
- 재생에너지 공급과 전력 수요의 불균형으로부터 나온 ramp event와 curtailment를 다룸
- At an even longer timescale
- Daily shifting에 필요한 것보다 큰 용량 또는 10시간 이상 큰 용량을 제공
- 하루 또는 그 이상의 용량을 제공
- 재생에너지 발전과 연관된 계절의 공급과 수요 불일치를 처리하는 데 사용될 수 있음
4. 결과
4-1. 출력 예측
CAISO(California Independent System Operator) market에서 개선된 단기 풍력 예측의 가치를 평가하고 시스템 전체의 잠재적 가치를 추정하기 위해 low wind scenario (SC4), high wind scenario (SC3) 두 가지 시나리오를 세우고 연구를 진행했다.

향상된 예측기법이 어떻게 오차를 줄이는 지를 보여주며, 예측을 통해 필요한 예비력을 감소시킬 수 있음을 확인할 수 있었다.
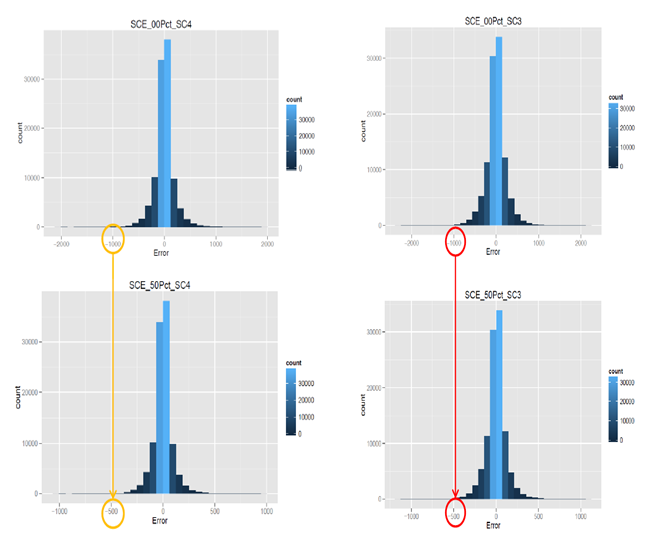
•Low wind scenario (SC4) data와 high wind scenario(SC3) data에 대해 persistence method 및 50%의 균일한 개선을 가진 예측을 사용한 오차 분포
•개선된 예측을 통해 오차의 분포가 좁아진 것을 볼 수 있음

4-2. ESS
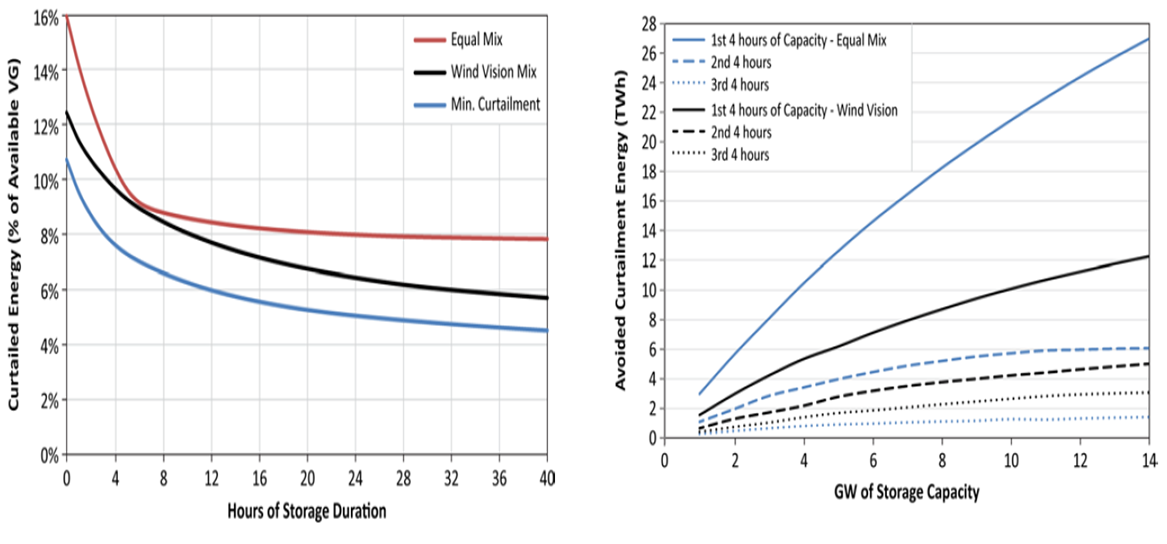
변동성 전원(VG, Various Generation)의 Curtailment를 줄이기 위해 사용되는 에너지 저장 장치의 가치와 저장기간을 평가
Scenarios
- U.S. Department of Energy’s Wind Vision 연구 기반
- 풍력발전의 국가 전력 공급의 최대 허용치 검토
- 2050년 독립된(isolated) ERCOT 계통에 VG가 55%의 전력 공급 시나리오
- 2016년 말 기준의 현존하거나 개발 중인 태양광과 풍력의 발전량을 시작으로 55%의 VG를 달성할 때까지 다양한 전원 믹스를 구성
55%의 VG를 구성하는 3가지 주요 시나리오
- Wind Vision : 44% wind, 11% photovoltaics (PV)
- Minimum curtailment : 37% wind, 18% PV
- Equal mix : 27.5% wind, 27.5% PV
Methods
각각 시나리오 상의 전력계통을 급전(dispatch)하기 위해 NREL의 REFlex 모델을 사용하고 curtailment를 방지하기 위해 에너지 저장장치의 사용을 분석
- NREL : National Renewable Energy Laboratory
- REFlex : Renewable Energy Flexibility
Wind generation profiles
- NREL Wind Toolkit의 데이터 사용
- 시간당 출력은 7,800개의 개별 사이트에서 생성되며, 각 사이트의 크기는 데이터 베이스의 자원 가용성에 따라 2~16MW이며 총 117GW의 잠재적 용량을 제공
- ERCOT의 기존 풍력 용량 위치를 시뮬레이션 풍력 출력 세트와 일치시켜 “기준“ 풍량을 설정
- 시뮬레이션의 풍력 발전 프로파일은 100m 허브 높이를 가정하기 때문에, 낮은 허브 높이를 가진 풍력 터빈에서 나온 과거 발전 레벨에 맞게 프로파일을 축소
- Wind site에 근접함을 기준으로 250MW급 400여 개의 군집으로 집계
Wind generation to the scenarios
각 군집의 증분 값 또는 에너지 및 용량 값의 합을 평가
- 2016년 가격/순부하 관계를 사용하여 매시간 에너지 생산량을 해당 시간의 한계 에너지 값과 곱하여 에너지 값을 계산
- ERCOT에서 새로운 용량의 추정 연간 값에 용랑크레딧을 곱하여 용량 값을 추정
- 용량 크레딧 : 상위 100시간 동안에서 군집의 평균 용량 계수
- 혼잡 방지를 위해 충분한 송전라인이 있다고 가정하며, 모든 curtailment는 송전 제약 조건과 반대로 시스템 생성 제약조건에서 비롯된다고 가정
- 이 반복적인 과정을 통해 모든 400개 군집에 대한 증분 값을 계산
PV generation to the scenarios
- SunShot 2030 study를 위해 생성된 PV site를 사용
- 상대적으로 부하 센터에 가깝지만 대규모 개발에 적합한 토지가 있는 지역의 “비용 최적(Cost Optimal)"조합을 파악하기 위해 ReEDS 모델에 의해 선정된 부지
- 약 108 GW의 용량을 나타내는 약 215개의 부지가 생성됨
- 6년 간의 연구 데이터에 대한 시간별 프로파일을 생성하기 위해 System Advisor Model을 사용하여 각 PV site를 시뮬레이션함
5. 결론
- 재생에너지원의 변동성과 불확실성은 전력 계통의 안정성에 영향을 줄 수 있는 요소로 반드시 다루어지고 해결되어야 하는 문제점임
- 재생에너지 보급의 확대는 세계적인 추세이며, 재생 에너지 침투를 높이기 위한 해결책으로 출력 예측 개선과 ESS가 있음
- 출력 예측 개선과 ESS를 통해 재생에너지의 비율을 확대할 수 있고 예비력 절감 및 curtailment 감소를 통해 경제적 효과를 볼 수 있음
Reference
- Antonanzas, Javier, et al. "Review of photovoltaic power forecasting." Solar energy 136 (2016): 78-111
- Voyant, Cyril, et al. "Machine learning methods for solar radiation forecasting: A review." Renewable Energy 105 (2017): 569-582.
- Hodge, Bri-Mathias, et al. Value of improved short-term wind power forecasting. No. NREL/TP-5D00-63175. National Renewable Energy Lab.(NREL), Golden, CO (United States), 2015.
- Denholm, Paul, and Trieu Mai. "Timescales of energy storage needed for reducing renewable energy curtailment." Renewable energy 130 (2019): 388-399.
'Energy > Sustainable Energy' 카테고리의 다른 글
| 전력산업 메가트렌드 - 1 (탈탄소화, Decarbonization) (0) | 2022.03.27 |
|---|---|
| [기후변화와 에너지산업의 미래] 신재생에너지로의 전환 (0) | 2022.03.19 |
| 소수경제 로드맵 이행을 위한 세부전략과 과제 - 3 (0) | 2021.10.24 |
| 소수경제 로드맵 이행을 위한 세부전략과 과제 - 2 (0) | 2021.10.24 |
| 소수경제 로드맵 이행을 위한 세부전략과 과제 - 1 (0) | 2021.10.24 |



