EDA(Exploratory Data Analysis)
- Exploratory data analysis (EDA) is used by data scientists to analyze and investigate data sets and summarize their main characteristics, often employing data visualization methods.
- 탐색적 데이터 분석으로 도표(Plot), 그래포(Graph), 요약 통계(Summary Statistics)등으로 시각화하여 데이터를 다양한 각도에서 관찰하고 이해하는 과정
PJT Code for EDA
1. Library Install
pip install plotly cufflinks pandas numpy seaborn matplotlib pandas-gbq
pip install chart-studio
pip install plotly --upgrade강의에는 아래와 같은 코드로 되어있었지만, 실행시켜보니 오류가 나왔었고 찾아보니 위와 같이 chart-studio와 plotly upgrade를 진행해야 실행이 되었다.
!pip3 install plotly cufflinks pandas numpy seaborn matplotlib pandas-gbq
2. Library Import
import chart_studio.plotly as py
import cufflinks as cf
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.style.use('ggplot')
print(cf.__version__)
%config InlineBackend.figure_format = 'retina'
cf.go_offline()3. 1월의 전체 Trip 수
%%time #불러오는 시간을 확인
query = """
SELECT
DATETIME_TRUNC(pickup_datetime, hour) as pickup_hour,
count(*) as cnt
FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2015`
WHERE EXTRACT(MONTH from pickup_datetime) = 1
GROUP BY pickup_hour
ORDER BY pickup_hour
"""
df = pd.read_gbq(query=query, dialect='standard', project_id='manifest-module-318307', auth_local_webserver=True)BigQuery에서 'bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2015'라는 공개 데이터셋을 불러오고 이 중 1월의 데이터를 불러오는 과정이다. 본인이 만든 project의 id를 확인하여 df를 입력할 때 잘 넣어주어야 한다. 처음 코드를 입력하면 로그인을 해야하는데 BigQuery에 project를 만든 google 계정으로 로그인하면 된다.

df.tail(10)총 744(0~743)개의 데이터가 나오는 것을 확인할 수 있다. (31X24)
df.info()
df['pickup_hour'] = pd.to_datetime(df['pickup_hour']) #시간을 datetime으로 바꿀 때는 pd.to_datetimedf = df.set_index('pickup_hour') #pickup_hour 기준으로 index 지정
df.head()df.iplot(kind='scatter',xTitle='Datetimes',yTitle='Demand',title='NYC Taxi Demand(2015-01)')scatter 형식의 그래프로 x축은 Datetimes, y축은 Demand, 제목은 NYC Taaxi Demand(2015-01)
전반적으로 규칙적인 패턴을 보이고 있으나 1월 27일 1시 - 6시 경 수요가 급격하게 줄어든 것을 볼 수 있다. 데이터 이상으로 의심할 수 있으나 2015년 1월 23일 큰 눈폭풍이 발생하여 전체 택시 Trip 횟수가 크게 감소했다고 한다. 이를 통해 날씨가 수요에도 영향을 미칠 수 있다는 것을 확인할 수 있다.
The January 2015 North American blizzard was a powerful and severe blizzard (January 2015 North American blizzard - Wikipedia)
4. Date 별 Trip 수
df['date'] = df.index.date
df.groupby(['date'])[['cnt']].sum().iplot()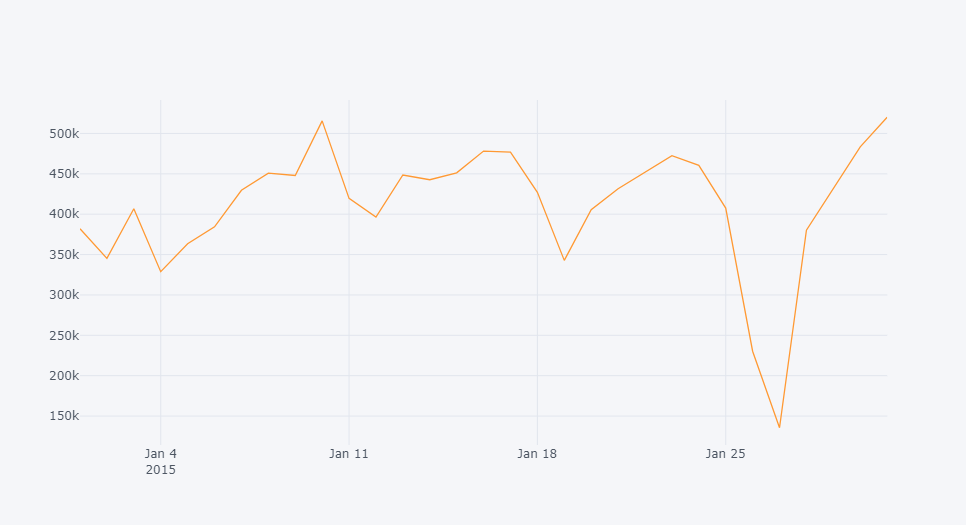
iplot의 경우 동적 그래프를 리턴하여 각 그래프의 각 포인트 마다의 값을 마우스 커서를 통해 확인이 가능하다.
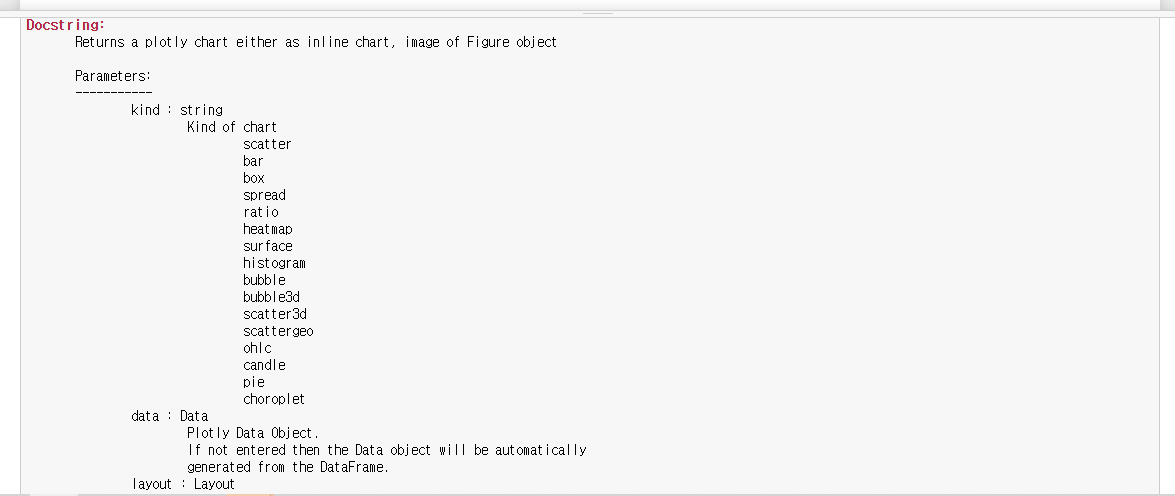
코딩을 진행하다가 모르는 부분이 나온다면 코드 뒤에 ?를 붙여서 해당 코드의 정보를 확인할 수 있다. 예를들어, 앞서 사용한 df.iplot에 대해 알고싶다면 df.iplo?을 입력하면 되고 아래와 같이 특징과 설명에 대한 정보를 알 수 있다.
df.iplot?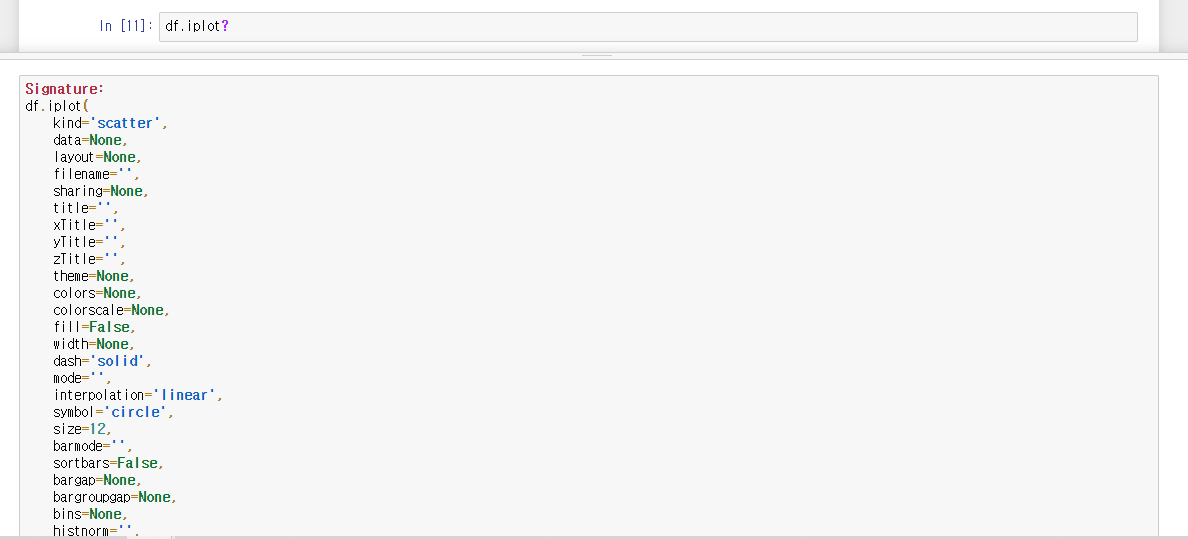
'Programming > Project' 카테고리의 다른 글
| [NYC 택시 수요 예측 PJT] 6. 데이터 전처리 (2) | 2021.07.27 |
|---|---|
| [NYC 택시 수요 예측 PJT] 4. 데이터 EDA - 데이터 시각화 (Time Domain) - 2 (0) | 2021.07.14 |
| [NYC 택시 수요 예측 PJT] 3. BigQuery 소개 (0) | 2021.07.11 |
| [NYC 택시 수요 예측 PJT] 2. 문제정의 (0) | 2021.07.11 |
| [NYC 택시 수요 예측 PJT] 1. 개요 (0) | 2021.07.11 |



